NVIDIA Grace CPU Superchip
![]()
NVIDIA Grace CPU Superchip
The hardware powering every Isambard 3 node
GW4 Isambard 3 Practical Workshop — 21 April 2026
![]()

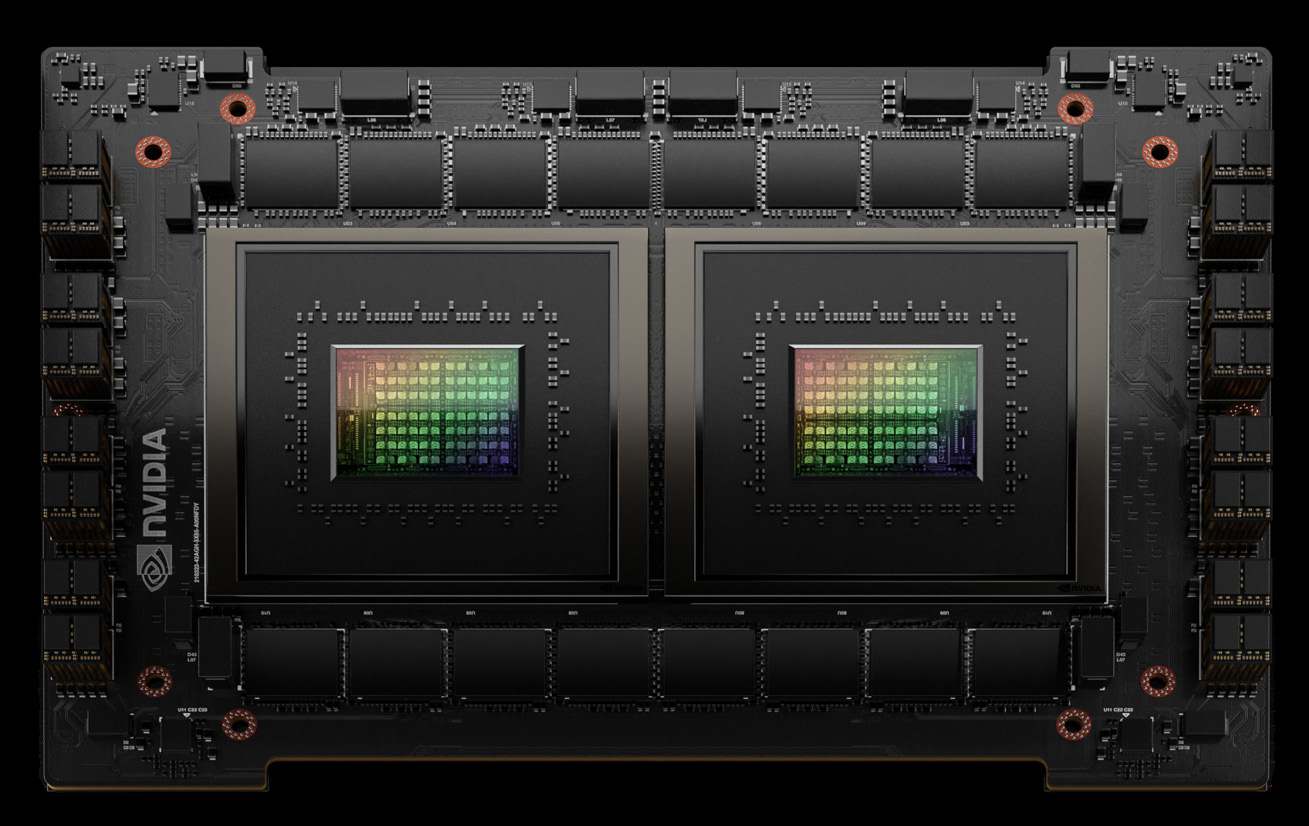
Two Grace CPUs in one module
A Grace CPU Superchip packages two NVIDIA Grace CPUs on a single compact module.
Cores
- 144 Arm Neoverse V2 cores across the Superchip
- 72 cores per Grace CPU
The interconnect
- The two CPUs are linked by NVLink-C2C (Chip-to-Chip)
- 900 GB/s bidirectional bandwidth between them — far faster than PCIe
This tight coupling is why the Superchip behaves more like a single processor than a conventional dual-socket server.
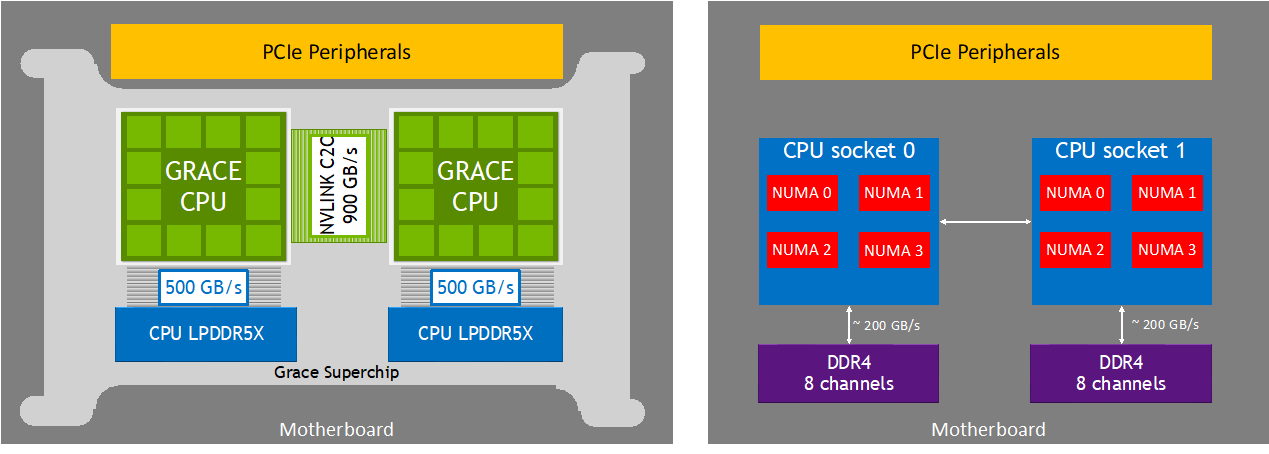
NUMA topology: simpler than a conventional server
Within each Grace CPU, cores, cache, memory, and I/O are connected by the NVIDIA Scalable Coherency Fabric (SCF) — a high-bandwidth mesh.
- One Grace CPU = one NUMA node
- One Superchip = two NUMA nodes total
- Cross-NUMA traffic travels the 900 GB/s NVLink-C2C link
Conventional dual-socket servers may expose four or more NUMA nodes with slow inter-socket interconnects. Grace is notably simpler.
Practical rule: treat each node as two NUMA zones, each with 72 cores and ~120 GB of memory.
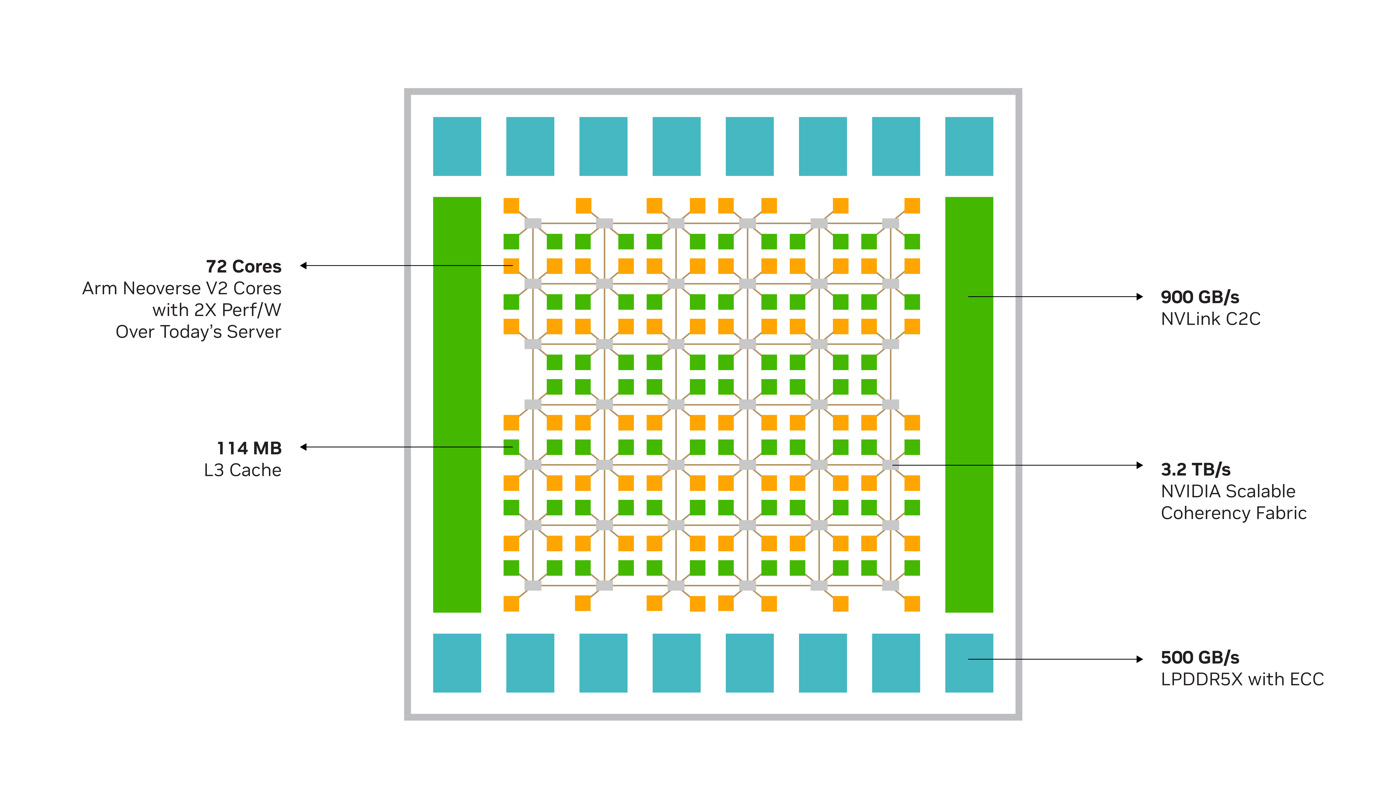
Inside a single Grace CPU die
Compute
72 × Arm Neoverse V2 cores
Cache hierarchy
- 64 KB L1 I-cache + 64 KB L1 D-cache per core
- 1 MB L2 cache per core (private)
- 114 MB distributed L3 cache shared across all 72 cores
Internal fabric
3.2 TB/s NVIDIA Scalable Coherency Fabric connecting cores, L3, memory, and I/O
Off-die link
900 GB/s NVLink-C2C to the second Grace CPU
Vectorization: SVE2 and NEON
Each Neoverse V2 core contains four 128-bit SIMD units supporting two instruction sets.
NEON
Fixed 128-bit width; the standard Arm SIMD set. Widely supported across compilers and libraries.
SVE2 (Scalable Vector Extension 2)
Armv9-A feature; also runs at 128 bits on V2, but written length-agnostically so it can target future wider implementations without recompilation.
Compiling for best performance
Use -mcpu=neoverse-v2 with the GNU
compiler (the recommended path on Isambard 3):
- GCC:
-mcpu=neoverse-v2 - Via Cray wrappers (
cc,CC,ftn): add-mcpu=neoverse-v2to your flags
-mcpu sets both the architecture target and the tuning
in one flag — it is the correct flag for Arm, unlike -march
which is the x86 convention.
